In-Sample与Out-of-Sample测试:解决策略过度拟合的关键方法
一、问题背景:为何策略回测有效但实盘亏损?
在量化交易中,常出现以下现象:
- 开发的策略在历史回测中表现优异(回撤小、盈利高),但上线后却持续亏损。
- 核心原因是过度拟合(Overfitting):策略在参数优化时过度适配历史数据中的噪声,导致对新数据失效。
传统观点认为“历史无法代表未来”,但反过来看:若策略在历史数据中都无法盈利,更难期待其在未来盈利。因此,合理的回测与优化是必要的,但需通过科学方法规避过度拟合。
二、核心概念:In-Sample与Out-of-Sample的定义
1. 统计学视角
- 样本内数据(In-Sample Data):用于策略开发和参数优化的历史数据(已知数据)。
- 样本外数据(Out-of-Sample Data):未参与优化、用于验证策略泛化能力的“未来数据”(未知数据)。
2. 传统回测的缺陷
- 方法:直接使用全部历史数据(如2017-2023年BTC数据)进行回测和优化。
- 缺点:
- 优化过程类似“开卷考试”,易因市场噪声选中偶然有效的参数(“幸运拟合”)。
- 策略仅适配特定历史模式,无法应对新市场条件。
三、In-Sample与Out-of-Sample测试的实践方法
1. 数据分割策略
步骤:
- 将历史数据划分为两部分:
- In-Sample(样本内):占比70%-80%,用于策略开发、参数优化(如2017-2021年数据)。
- Out-of-Sample(样本外):占比20%-30%,用于验证优化后的策略(如2022-2023年数据)。
- 在样本内进行充分优化(参数调整、逻辑迭代),不担心过度拟合,因目标是暴露策略缺陷。
- 用样本外数据模拟实盘环境,检验策略泛化能力。
- 将历史数据划分为两部分:
分割比例权衡:
- 样本外数据越多,验证越严格(对新数据适应性要求高),但样本内数据减少可能增加开发难度。
- 建议初始采用7:3或8:2分割,参数越多、优化复杂度越高,需保留更多样本外数据。
2. 关键注意事项
- 禁止“数据渗漏”:
- 样本外数据必须完全未参与策略优化(包括参数调整、逻辑修改)。
- 错误示例:
若样本外验证失败后,基于其结果修改策略或参数,会将样本外数据变为“隐性样本内数据”,丧失验证意义。
- 避免“参数孤岛”:
- 优化结果中,若某组参数在样本内表现优异但周围参数均亏损(形成“孤岛”),极可能是过度拟合产物。
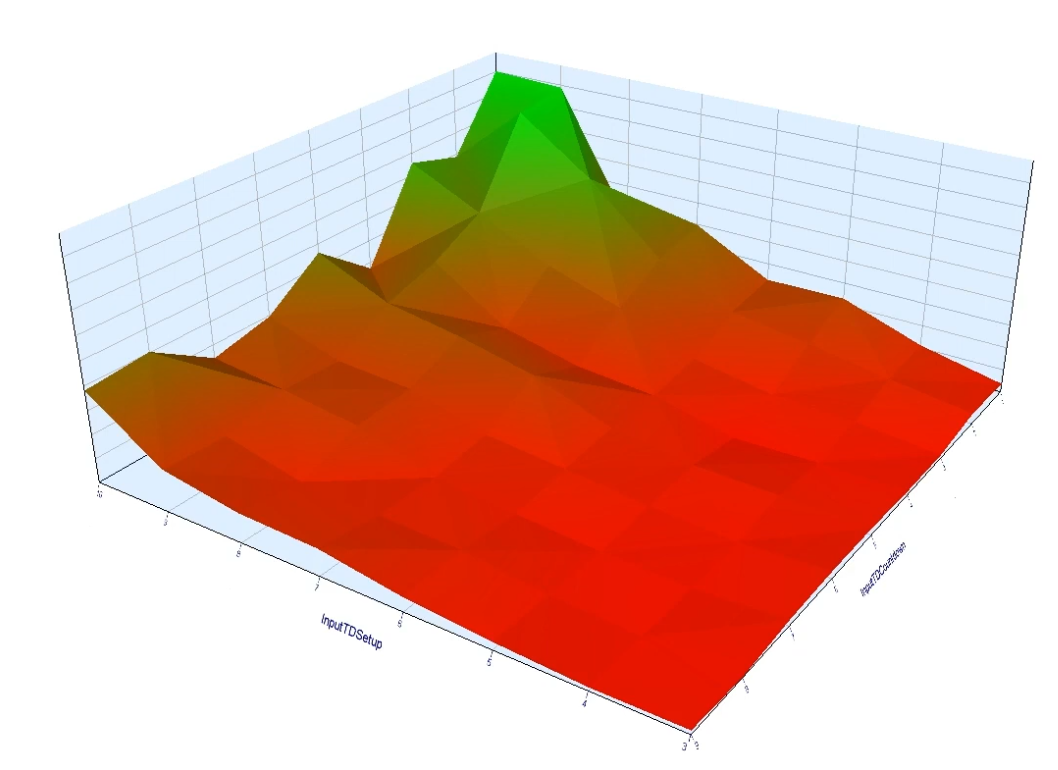
- 应选择“参数高原”区域的参数(附近参数组合表现稳定),降低对特定噪声的依赖。
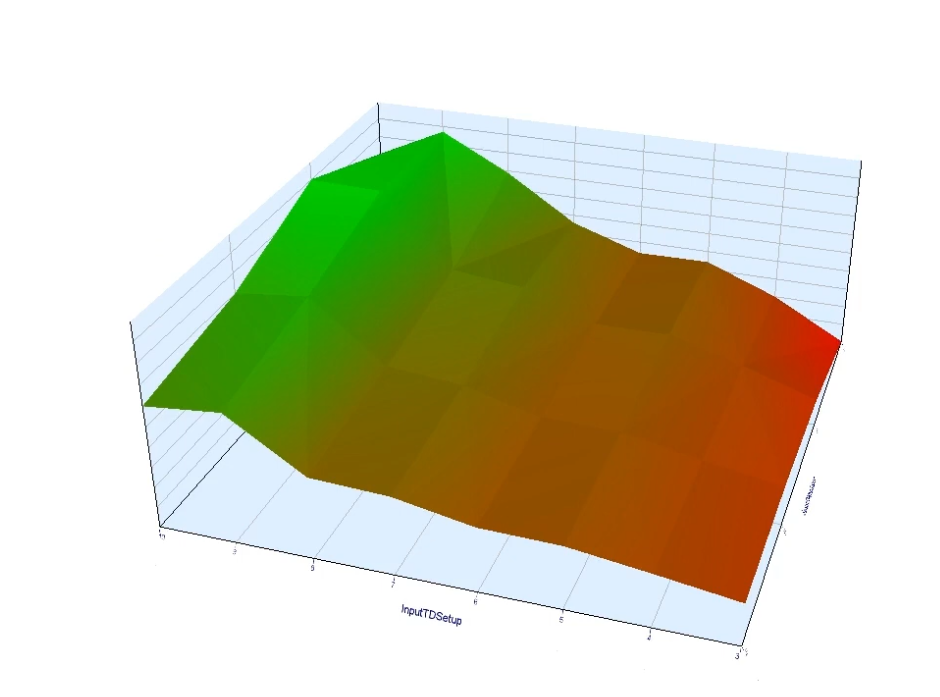
- 优化结果中,若某组参数在样本内表现优异但周围参数均亏损(形成“孤岛”),极可能是过度拟合产物。
四、MT5平台实操演示(以BTC数据为例)
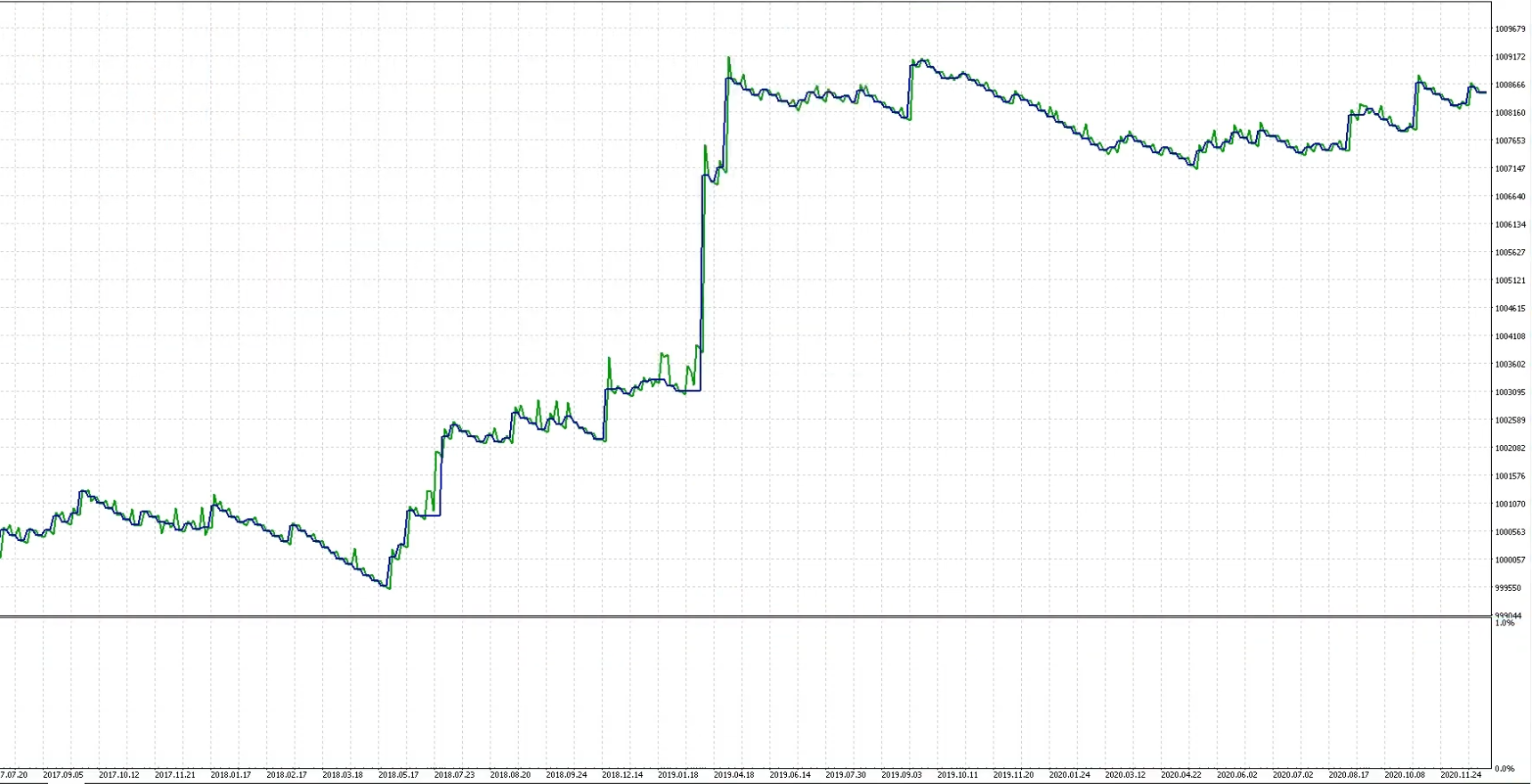
1. 样本内优化(2017-2021年)
步骤:
- 输入参数范围(如3个参数,共288种组合),选择优化目标(如“最大结余”)。
- 运行完整优化或快速遗传算法,筛选绩效指标(盈利因子>1.5、交易笔数>200笔)。
- 分析权益曲线,确保策略在样本内稳定盈利(非偶然拟合)。
参数1
参数2
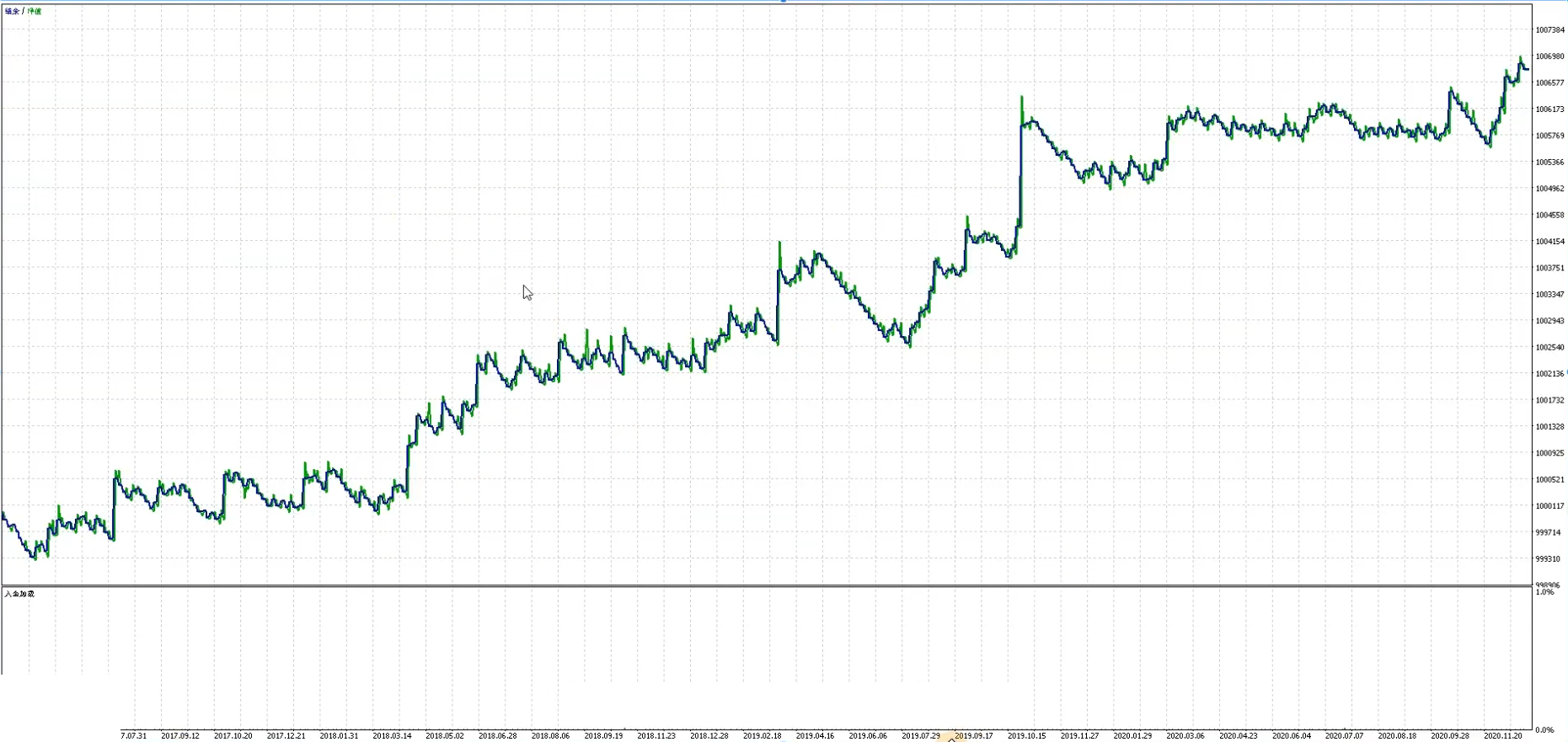
2. 样本外验证(2021-2023年)
步骤:
- 固定样本内优化得到的参数,切换时间范围至样本外数据。
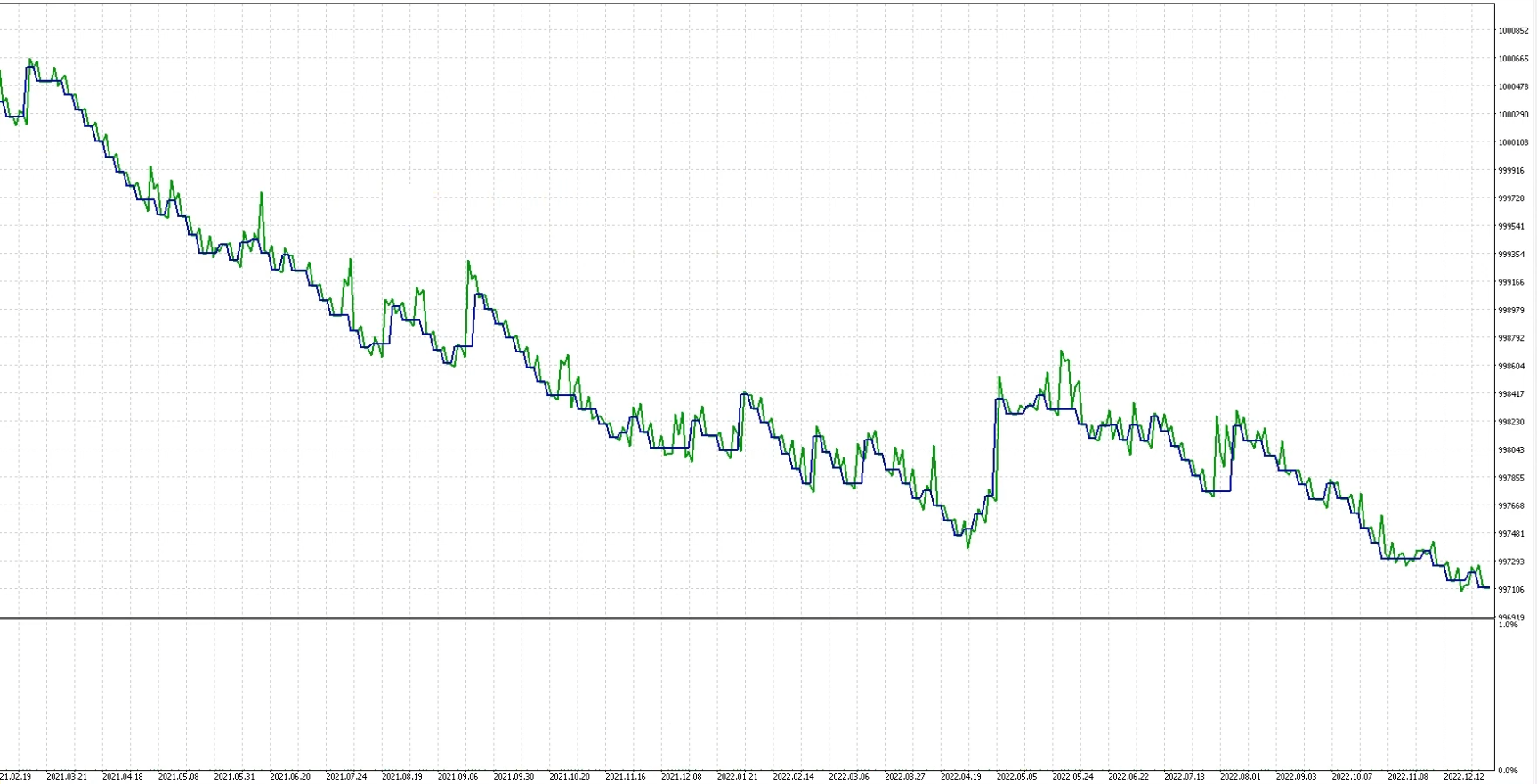
- 运行回测,对比关键指标(如盈利因子从1.74骤降至0.66,提示过度拟合)。
- 仅接受在样本外仍保持正向收益的策略,拒绝依赖历史噪声的“虚假有效”参数。
参数1
参数2
结论
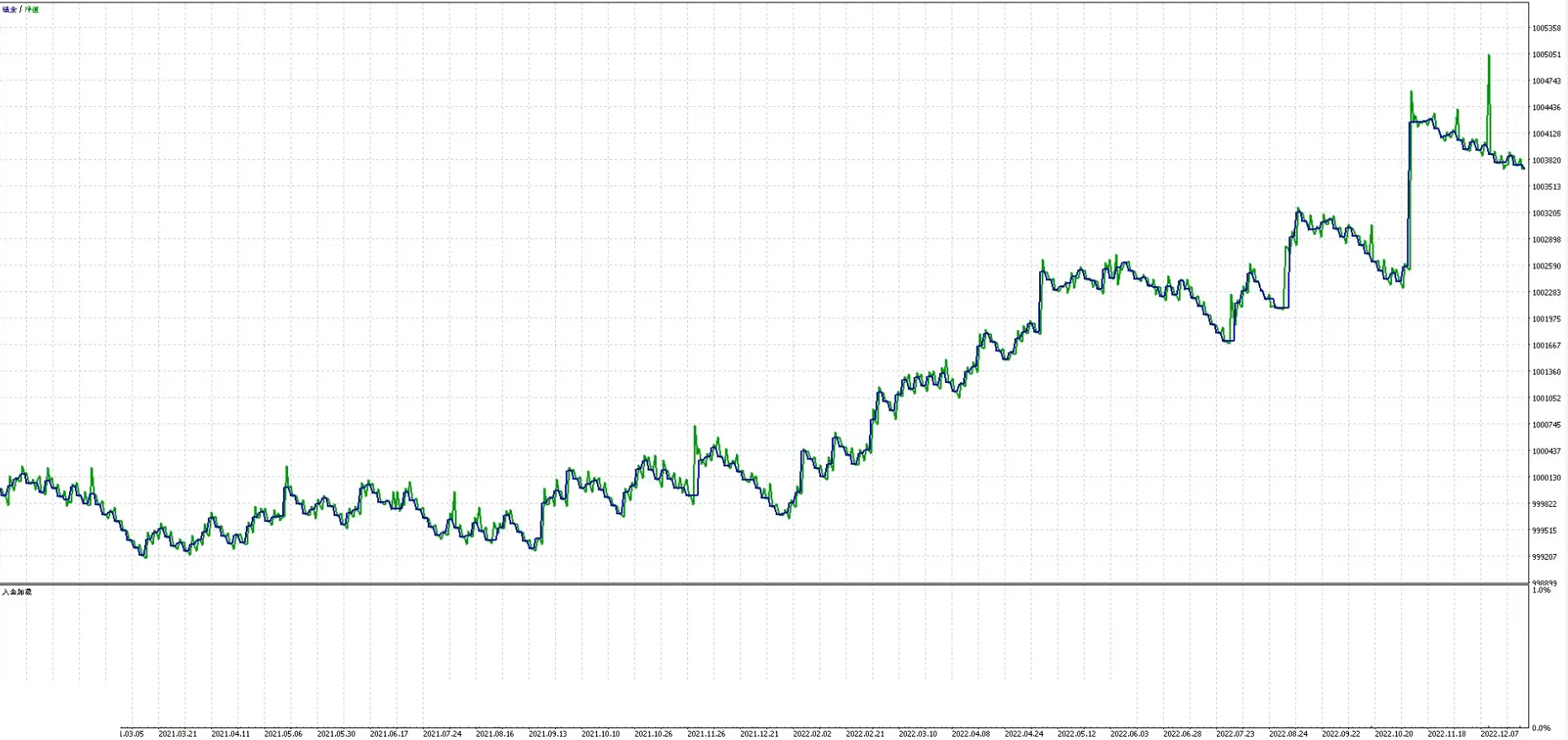
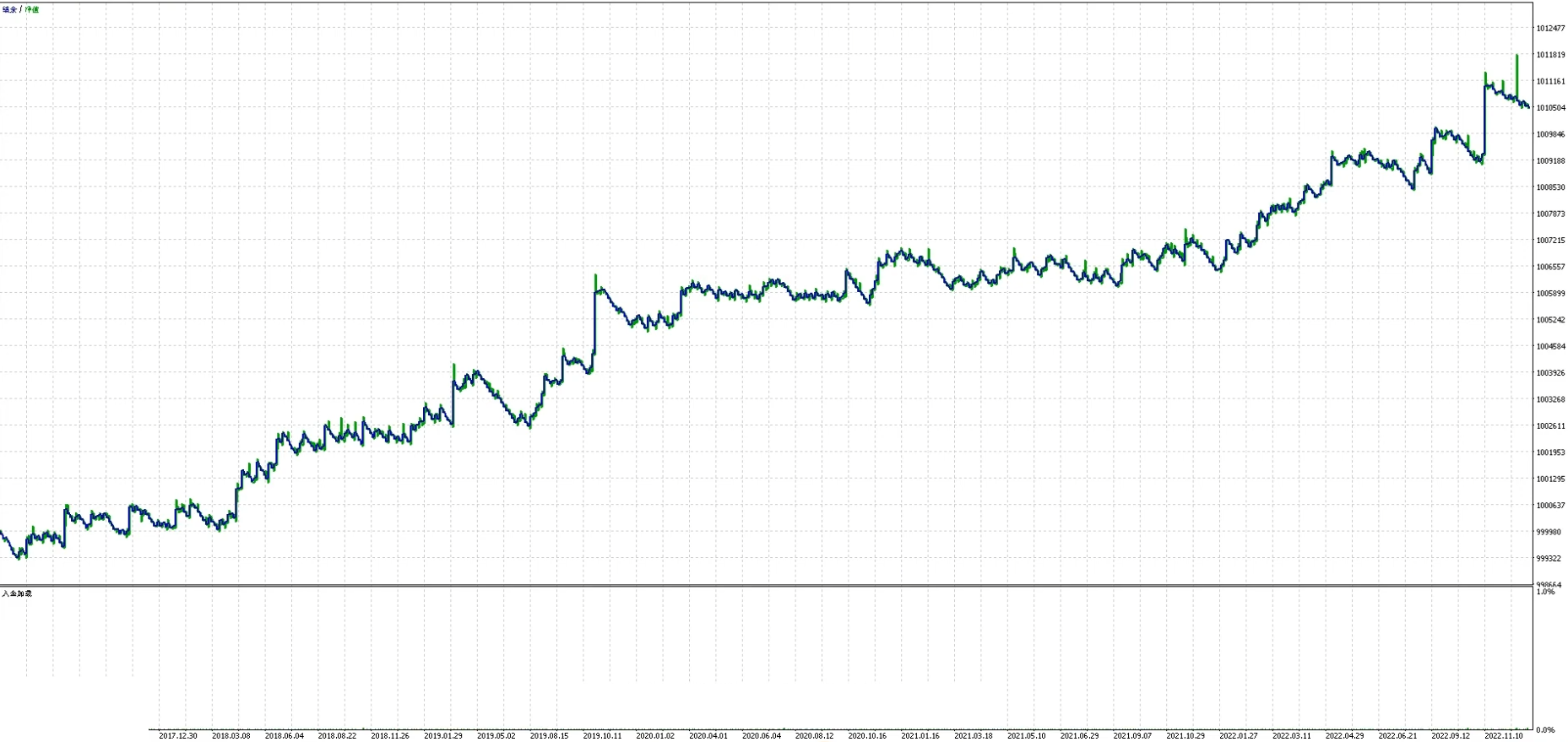
对比发现参数1在样本外表现糟糕,参数2在样本外表现更好,因此采用参数2,以下是参数2样本内样本外整体曲线
五、扩展:数据三分法(训练集、测试集、验证集)
- 三部分划分:
- 训练集(Training Set):用于策略逻辑开发(占比50%-60%)。
- 测试集(Testing Set):验证训练集优化效果,调整参数(占比20%-30%)。
- 验证集(Validation Set):最终检验策略泛化能力(占比10%-20%)。
- 优势:更严格规避过度拟合,适合复杂策略或多参数优化场景。
- 注意:流程复杂度增加,需平衡开发成本与策略可靠性。
六、总结:科学量化的核心原则
- In-Sample测试:是策略开发的“实验室”,允许试错与优化。
- Out-of-Sample测试:是策略上线的“质检关卡”,强制验证泛化能力。
- 核心目标:通过数据分割与严格验证,筛选出真正具备统计优势(而非偶然拟合)的策略。
记住:量化交易的产出比本就应偏低——若每开发一个策略都“有效”,反而是流程存在严重问题的警示。唯有通过严谨的样本内外测试,才能在历史规律与未来不确定性之间找到平衡。